How to Choose Between Scale-up Open ZFS vs. Scale-out Ceph Storage Clusters

Many enterprise and midsized organizations are evaluating Ceph to address the exponential rise in data created outside the data center. However, deploying, managing and administering a large-scale storage cluster infrastructure can be daunting, even for an experienced organization.
Ceph’s elastic architecture features the ability to expand a storage cluster by simply adding or removing hardware – even while the system is online or under a heavy load. As a result, efficiently scaling a Ceph hardware architecture is critical to reduce overspending while maintaining the ability to accommodate peak capacity and performance requirements in distributed workloads, such as that artificial intelligence, dynamic cloud, IoT and edge computing.
Researching Ceph storage cluster solutions to achieve new levels of performance and efficiency? Here’s what data center administrators need to know to evaluate OSNEXUS object storage solutions. Questions? Drop us an email at

⚖️ Choosing Scale-up vs. Scale-out Architectures
Pogo Linux has worked with many IT departments who have turned to Ceph as a highly-available, open source storage cluster solution to expand distributed storage environments on-premises, on public and private clouds, and at the edge. In that process, we’ve identified key tradeoffs of scale-up vs. scale-out approaches to help data center operators select the best software and hardware architecture for various workload and services environments.
In this article, we’ll share some of that expertise, by explaining the different approaches to a successful software-defined storage strategy – whether that’s scale-up, scale-out, or a combination of the two – as both options have technical merit based on individual use-case.
To begin, we look at the budget, capacity, performance, storage protocol and high-availability requirements for each workload and match that to a best fit for scale-up or scale-out storage cluster options:

A scale-up cluster vertically scales, like a traditional SAN/NAS file system (file, block), by adding hardware resources (storage media and expansion enclosures) to a two server configuration. They provide a compact and cost-effective solution that is ideal for workloads with performance requirements up to 3GB/sec and capacity up to 2 petabytes per storage pool.
Conversely, a scale-out cluster horizontally scales across racks while delivering file, block and object storage. These systems expand by adding server nodes, storage media and/or storage enclosures (JBODs/JBOFs). Scale-out architectures provide a single namespace so that all capacity can be accessed via a single NAS folder or S3-compatible bucket.
This architecture has the benefit of scaling performance and capacity as additional servers and storage media are added to the cluster. As such, scale-out architectures are ideal for object storage and use-cases that need unbound capacity and performance to meet the needs of large-scale HPC, research archives, or CDN’s that require the ability to scale to 100 petabytes or more.
⚡ QuantaStor Ceph Storage Clusters
Fortunately, the OSNEXUS QuantaStor software-defined storage (SDS) platform supports both scale-up (OpenZFS) and scale-out (Ceph) architectures, and provides the fastest way for organizations to start small and grow to their storage environment to hyperscale size with ease.
The QuantaStor platform bare-metal installs on each storage server, either as an upgrade for RHEL/CentOS 8, or as an all-in-one, bare-metal ISO installed on Ubuntu LTS. Deploying new storage clusters, creating storage pools for file, block and object storage has never been easier, and can be done completely via the QuantaStor web user interface in minutes with no prior Linux or Ceph experience.
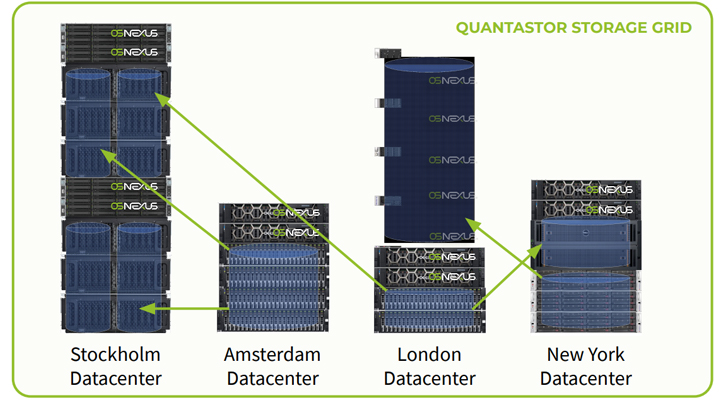
- Storage Grid – The QuantaStor storage grid simplifies management by combining storage servers into a “grid” so that they can be collectively managed across sites as one.
- Security – More importantly, the storage grid technology makes it easy for organizations to implement strong NIST complaint security enforcement practices for hybrid cloud strategies.
- Management – Where alternative storage solutions offer a simple dashboard, QuantaStor provides a comprehensive web management interface that’s simultaneously accessible from all systems within a given storage grid with no additional software to install.
📋 Expansion Considerations
QuantaStor supports all major storage media types (NVMe, eSATA, NL-SAS) to enable easy and cost-effective expansion of scale-up or scale-out storage cluster environments.
- Grow Capacity – For capacity-focused architectures, add high-density JBOD expansion enclosures directly on the network or direct-attached storage (DAS) systems with SAS-SATA interfaces to any server node appliance.
- Increase Performance – For performance-built architectures, add all-flash storage via NVMe-over-Fabrics (NVMe-oF) or SAS-based expansion enclosures.
QuantaStor servers within the storage grid can be comprised of a heterogeneous mix of hardware from different OEM vendors to deliver unprecedented hardware flexibility and agility to expand. Storage grids may also include multiple independent scale-up and scale-out clusters using a mix of storage media types, making it easy to deploy storage pools to meet specific workloads.
📈 Scale-out Architecture Benefits
The concept of horizontally ‘scaling out’ the hardware architecture means adding more components to the solution in parallel to spread out a load. Scale-out SAN/NAS clusters are unified storage platform (file, block, object), designed to grow in performance with unbound capacity by adding more server nodes to the cluster.
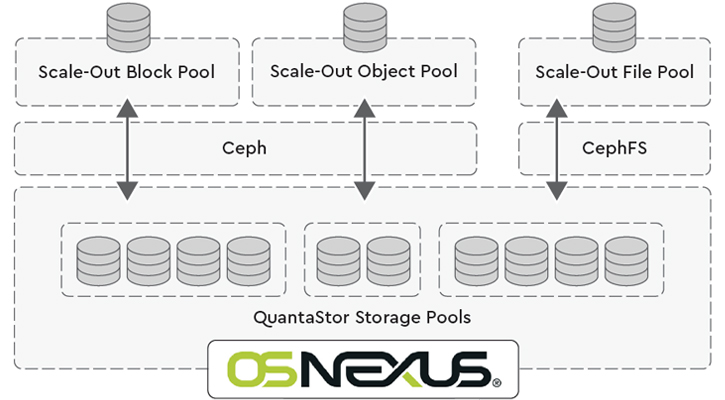
Without capacity constraints, scale-out configurations can keep scaling and are more versatile than scale-up solutions, as they provide simultaneous support for file, block and S3-compatible object storage environments.
In single ‘shared-nothing’ storage design, QuantaStor users can aggregate storage from multiple appliances to manage a broad range of applications, including OpenStack cloud deployments.
- Storage Protocols – QuantaStor integrates with standard Ceph 14/15/16 storage technology to support all file (NFS, SMB, CephFS), block (iSCSI, FC, NVMe-oF, RBD) and object storage (S3-compatible) storage protocols.
- Architecture – A scale-up cluster storage architecture is generally composed of 4 or more head-nodes that combine compute, networking and storage resources that are configured for high-availability (active/active replication).
- Scalability – The QuantaStor storage grid expands to over 100 petabytes per storage grid.
- Expansion – Grow capacity by adding JBOD-JBOF expansion enclosures directly on the network via composable fabric (NVMe-oF RDMA), or DAS systems.
- High-Availability – Scale-out architecture are implicitly highly-available at a file-system level with erasure-coding and replica-based data distribution technology to enable high-availability and fault-tolerance. At the same time, QuantaStor’s cluster VIF management technology ensures continuous access to NFS, SMB, iSCSI and NVMe-oF clients, while FC ALUA is used to provide continuous availability to FC connected hosts.
Upfront Cost – In terms of total hardware deployed, this initial higher-cost investment – coupled with server and networking port add-ons – is much greater than a scale-up configurations. The larger footprint to get started is the primary challenge to deploying a scale-out Ceph-based QuantaStor cluster architecture.
📊 Scale-up Cluster Benefits
The concept of vertically ‘scaling up’ the hardware architecture means making the solution larger or faster to handle a greater load. Scale-up storage clusters are traditional SAN/NAS for file and block storage, designed to grow in performance and capacity under 4 petabytes by adding hardware resources (compute, networking, storage) to a cluster.
In a lower-cost, compact footprint, QuantaStor users can aggregate storage from multiple appliances to support group shares in a global namespace, manage unified storage environments, or automation data replication.
- Storage Protocols – QuantaStor scale-up storage configurations integrate with OpenZFS storage technology to deliver file (NFS/SMB) and block (iSCSI, FC, NVMe-oF TCP) storage capabilities.
- Architecture – Scale-up clusters are composed of 2 or more QuantaStor servers that manage one (or more) storage pools that can dynamically move between servers (head-node controllers) for high-availability.
- Scalability – The QuantaStor storage grid expands to over 100 petabytes per storage grid, and may be comprised of scale-up and scale-out storage pools.
- Expansion – Add JBOF-JBOD expansion enclosures via DAS or NVMe-oF to any server – up to 600+ devices, up to 8 petabytes per cluster.
- High-Availability – Scale-up architecture uses head-node controllers configured for I/O fencing and highly-parallelized HA failover system to ensures automatic failover of ZFS-based storage pools. At the same time, remote replication schedules make it easy to replicate file and block storage on the storage grid. Using HA failover and data replication, storage pools can be automatically moved between QuantaStor appliances.
- Limitations – Scale-up configurations are limited by the bandwidth of server architecture in the cluster. Using 100GbE and fast storage media most use cases may be addressed, but workloads requiring rack-scale and multi-rack configurations often benefit from a single namespace scale-out design.
Upfront Cost – For solution requirements less than 2 petabytes, the compact footprint of a scale-up architecture is more cost-effective than an equivalent scale-out configuration. In terms of total hardware deployed, this lower-cost investment to get started is the primary benefit to deploying a scale-up OpenZFS-based QuantaStor cluster.
Choosing an Ceph Storage Cluster Management Solution
Low latency or high transfer rates are of little benefit if they swamp the target application. While these systems generate IOPS approaching the millions, the reality is that there are very few workloads that require more than the performance of these systems. However, there is an emerging class of workloads that can take advantage of all the performance and low latency of an end-to-end NVMe system.
If you’d like to learn more about how to maximize your data center infrastructure by up to 90% while minimizing its footprint, give us a call at (888) 828-7646, email us at or book a time calendar to speak. We’ve helped organizations of all sizes deploy composable solutions for just about every IT budget.
